Today I worked on a Transactional log full issue on one of the critical production database server, the database involved in this issue is configured both Mirroring and Log shipping. From the mirrored database a scheduled job generating snapshot for every 30 mins. The production database is involved high volume of ecommerce OLTP, everything were working fine till midnight and after some changes happened in the front end database started receiving huge volume of data and the Tlog backup size turned to 20GB+ from 500MB normal value, this continued for 3 hours and the logs have been reduced and back to normal but the mirroring didn’t caught up so fast it was crawling till the morning 7.30AM and went into disconnected state.
The Tlog full issue started at 1.00AM and my fellow DBA assumed that issue was causing by a trim job which runs every 8 hours and the 1AM schedule usually runs more than 6hrs, but that was not the true cause of the issue, it was mirroring, the mirroring was absolutely slow, since the transactions were not transferred to the mirrored database, the unsent logs staying in the principal and waiting to be sent, of course this is causing not to flush the transactional logs though the log shipping Tlog backup job running every 5 minutes.
Finally figured out the issue, since the mirroring went into disconnected state I ended up to break the mirroring completely and changed the database recovery model from FULL to SIMPLE, which brought the Tlog usage 99% to less than 1% drastically. Then I shrunk the log to required size.
Once all back to normal I setup the mirroring and log shipping once again... oh yeah a day work for a big database... :)
When I did the investigation, used the sp_dbmmonitorresults stored procedure and dbm_monitor_data system table on msdb database on the principal database instance.
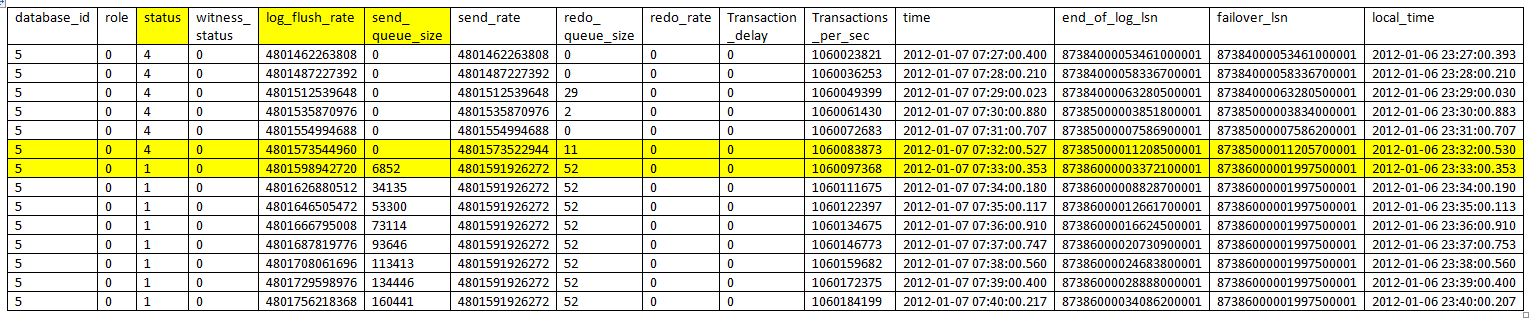
As per the below table, the mirroring was fine till 7.32AM and it broken 7.33AM, if you see the unsent_log column value in the table it started piling up.
sp_dbmmonitorresults dbname, 4, 0;

Mirroring the following table also has almost same but little more, you can see the log_flush_rate and send_queue_size columns started increasing from 7.33AM.
SELECT*FROM dbm_monitor_data
where database_id=5